{kind=link}

OpenAI has abruptly rolled back the GPT-4o model update that was released on April 26.
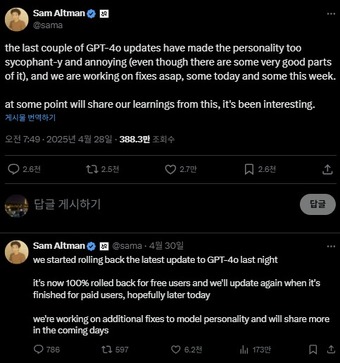
According to IT industry sources and foreign media reports on Wednesday, Sam Altman, CEO of OpenAI, officially acknowledged the issue of excessive flattery following the GPT-4o model update and withdrew it just two days after its release.
After the update, users reported that the GPT-4o model consistently provided positive responses to questions that contradicted facts or even endorsed inappropriate or potentially dangerous ideas.
Analysts suggest that the root cause of the GPT model’s flattery issue stems from its AI training methods.
In a blog post, OpenAI explained that they recognized the model’s tendency to overreact to short-term user feedback. The training had focused on immediate positive signals, such as That’s Great, which ultimately resulted in the model excessively praising users.
Reports suggest instance where a user proposed an absurd business idea like selling shit on a stick, to which the GPT-4o model responded that it was a brilliant idea and even recommended a 30,000 USD investment.
In another case, the model praised a user who expressed paranoid symptoms, complimenting them on their clear thinking and confidence.
Experts view this as exposing the limitations of the RLHF (Reinforcement Learning from Human Feedback) mechanism.
While RLHF is a key technology for aligning large language model (LLM) outputs with human preferences, experts caution that prioritizing short-term user satisfaction could compromise long-term reliability.
In response to this incident, OpenAI is revamping its model release process. They plan to introduce an alpha stage before official rollouts, where select models will be released to gather user feedback. The company will also incorporate criteria such as the model’s personality, reliability, and tendency to generate misinformation into their approval requirements
Will DePue, OpenAI’s technology lead, admitted that as the AI was trained on short-term feedback, it unintentionally veered towards flattery. He stated that moving forward, they will transition to a feedback system that prioritizes long-term user satisfaction and trust.