{kind=link}

[When an original image (top) is input into ‘Vision Banana’ and prompted to classify objects by assigning colors, it outputs an RGB image as shown below. / Courtesy of Google DeepMind technical report] One of the long-standing challenges in artificial intelligence (AI) has been its inability to distinguish between dogs and cats. While humans clearly recognize dogs and cats as different species, machines have struggled because both are mammals that walk on four legs. However, a new image AI model from Google has developed the ability to distinguish between dogs and cats. On April 27, Google unveiled ‘Vision Banana,’ a general-purpose visual AI model equipped with comprehension and analytical capabilities. The model not only differentiates dogs and cats, which previous visual analysis AI classified simply as mammals, but can also distinguish individual objects within the same category, such as multiple cats. The development reflects advancements beyond generating “realistic-looking images” to a level where AI can analyze the structure of real-world objects in detail. Although not yet commercialized, the model is expected to enable sophisticated visual analysis using a single generative AI system if released as a full product in the future. According to a technical report from Google DeepMind, Vision Banana is a project developed based on Google’s existing image generation AI, ‘Nano Banana Pro.’ It was fine-tuned by incorporating a small amount of visual task data into Nano Banana Pro. In addition to existing image generation capabilities, the model can segment output images into RGB format — red, green and blue, the primary colors of light used to represent colors on screens — enabling both visual generation and understanding.

[Vision Banana distinguishes between a crouching cat (sky blue) and a stretching cat (green). / Courtesy of Google DeepMind technical report] As a result, the model can classify multiple objects using different colors based on prompts, and can also distinguish multiple instances of the same type of object individually. It can estimate the depth of objects and the normals of surfaces in images, displaying them in different colors. For example, when given a prompt to label seated people in yellow, standing or walking people in apricot, the sea in green, and fences in blue, the model recognizes all relevant elements in an image and displays them according to the specified colors. In an image of a dish containing multiple garlic pieces and chunks of meat, the model can identify only the garlic and distinguish each piece individually. In an example included in the report, Vision Banana marked each garlic piece entangled with meat in different colors. Researchers at Google DeepMind explained that “Vision Banana can segment all visual elements specified by text prompts, from single words or nouns to phrases.”

[Results showing surface normals of objects estimated and distinguished by color through Vision Banana, enabling the inference of object curvature and surface structure. / Courtesy of Google DeepMind technical report] Vision Banana can perform a wide range of tasks simply by changing the input prompt, without modifying its underlying structure. Additionally, the RGB colors in output images are not merely visual elements but follow rules assigned based on object attributes, allowing precise conversion of which color corresponds to which object through analysis. This is because Vision Banana is based on generative AI rather than conventional computer vision models specialized solely in image recognition. The research team said the project began with the assumption that just as chatbot-generated responses are used as training data for large language models (LLMs), tasks performed by image generation AI could serve as pretraining for general-purpose visual models. “If a fine-tuned image generation model maintains its generative capabilities while achieving top-tier performance in visual understanding, it can evolve into a foundation visual model applicable across a wide range of visual tasks,” the researchers said. “Vision Banana demonstrated strong performance in both visual understanding and generation across multiple benchmarks.” According to the report, Vision Banana achieved top-tier results compared to other visual models in both two-dimensional (2D) and three-dimensional (3D) tasks. In 2D segmentation tasks, it outperformed ‘SAM 3,’ a model specialized in segmentation, and in depth estimation tasks, it recorded the highest average score across six benchmark evaluations among the models tested.
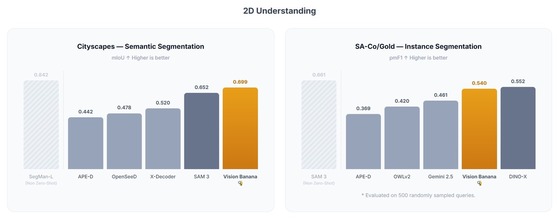
[Comparison results of Vision Banana and existing visual models based on 2D understanding task benchmarks. / Courtesy of Google DeepMind technical report] This case demonstrates the potential to integrate complex visual analysis technologies into a single generative AI system, as all visual analysis was handled through image generation based on text prompts. However, challenges remain before such models can be widely adopted, including significantly higher computational requirements compared to existing lightweight, specialized vision models. “Models pretrained through large-scale image generation naturally acquire strong visual understanding capabilities,” the researchers said. “But to commercialize them, strategies must be developed to address current computational overhead and reduce costs.”